Feminist Search Engine
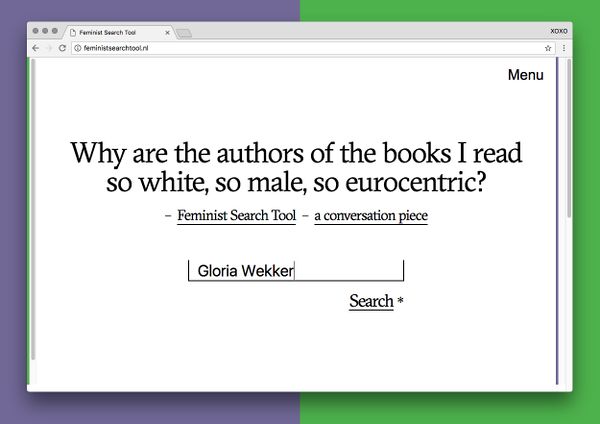
In collaboration with Utrecht-based art & research collective Read-in Hackers & Designers developed a Feminist Search Tool *,–a digital interface that invites users to explore different ways of engaging with the records of the Utrecht University Library, putting forth the question: Why are the authors of the books I read so white, so male, so Eurocentric? .
The tool has been developed in the context of the project Unlearning My Library. Bookshelf Research , and functions as an awareness-raising tool to stir conversations about the inclusion and exclusion mechanisms that are inherent to our current Western knowledge economy. To this end, the Feminist Search Tool invites us all to reflect about our own search inquiries, and how the latter may be directed by our own biases and omissions. More broadly, it raises the question about the different decisions taken that influence our searches: Who is taking responsibility for which part of the search process: we, the users, the researcher, the library, the algorithm? And how does this influence our search result?
The Feminist Search Tool works with a search field, which we all can use to type in our search question. We then search within a selection of the records of the Utrecht University Library of works published in the period of 2006 till 2016. The selection is made by Read-in and is based on a number of MARC21** fields, that Read-in thought would speak to the question: How many female non-Western authors and female authors of colour are represented in the Catalogue of the Utrecht University library? , such as language of publication, place of publication, type of publisher, ect. Through an interpretation of these fields, Read-in aims to offer different filters, through which to look at the records of the Utrecht University library.
The tool will be launched on the occasion of Zero Footprint Campus
Footnotes as written by
Read-in
for the website of the
feminist search tool
- Using the term Feminist Search Tool, it is important to shortly comment on our understanding of the term feminism, to provide a context, in which to read the Feminist Search Tool . Our commitment to and understanding of feminism is an intersectional one.
- MARC21 (abbreviation for Machine-Readable Cataloguing) is an international standard administered by the Library of Congress; it is a set of digital formats used to describe items that are catalogued.
fst
setup
local web-server
to run a local web-server to test the frontend, we assume Python3 is available. Do:
python3 -m http.server
and point your web browser to
localhost:8000
.
solr
-
install
apache solr, official docs -
make two new cores, named
readin-fstandname2gender, with the following command ( ref ):
cd /opt/solr
sudo -u solr ./bin/solr create -c <core-name>
sudo ls -la /var/solr/data // check folders are created
-
run
python parser.py /path/to/readin.xml.
the current VPS cannot handle parse a 30MB XML file so we need to run this on our machine.
afterwards, upload the two folders
name2gender
and
readin-fst
from your local SOLR installation (eg under
./solr/server/solr
) to the VPS, and move each folder under
/var/solr/data
and fix the file + folder permissions:
sudo chown -R solr:solr /var/solr/data/readin-fst
sudo chown -R solr:solr /var/solr/data/name2gender
reload each SOLR core:
curl "http://localhost:8983/solr/admin/cores?action=RELOAD&core=name2gender"
curl "http://localhost:8983/solr/admin/cores?action=RELOAD&core=readin-fst"
then, add a new proxy pass in your
nginx
or
apache
config file:
-
nginx, inside the main
serverblock:
location /solr {
proxy_pass http://localhost:8983/solr/readin-fst/query;
}
-
apache, before
</VirtualHost>:
ProxyRequest Off
ProxyPreserveHost On
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
ProxyPass /solr http://localhost:8983/solr/readin-fst/query
for this to work, make sure to enable
sudo a2enmod proxy
and
sudo a2enmod proxy_http
, otherwise Apache can't do the
ProxyPass
and query the solr database (
ref
).
solr help
In case solr stops, or fails etc, try to simply restart it by doing
sudo service solr restart
it will restart the process under the
solr
user on the appropriate port (eg
8983
). this is using the
init.d
process.
to check the SOLR log:
sudo cat /var/solr/logs/solr.log
VPS and SOLR swap memory
make sure the VPS / VM has a swap file of 2gb or so, otherwise SOLR does not run. see for eg https://www.devtutorial.io/how-to-create-swap-space-on-debian-12-p3119.html .
VPS and SOLR ulimit
SOLR requires 65000 as limit for ulimit hard and soft settings. add the following to
/etc/security/limits.conf
:
solr soft nofile 65000
solr hard nofile 65000
solr soft nproc 65000
solr hard nproc 65000
Java 11 for SOLR v7.5
in the process of downgrading from SOLR 9.5 to 7.5, we also had to downgrade the Java version used.
while SOLR asks for Java 8 JRE, we can install version 11. do:
$ wget https://download.java.net/openjdk/jdk11/ri/openjdk-11+28_linux-x64_bin.tar.gz
$ tar xvf openjdk-11+28_linux-x64_bin.tar.gz
$ sudo mv jdk-11*/ /opt/jdk11
$ sudo tee /etc/profile.d/jdk.sh <<EOF
export JAVA_HOME=/opt/jdk11
export PATH=\$PATH:\$JAVA_HOME/bin
EOF
$ source /etc/profile.d/jdk.sh
$ echo $JAVA_HOME
$ java -version
(ref https://techviewleo.com/install-java-11-openjdk-11-on-debian-linux/?expand_article=1 )
SOLR 7.5 still uses a hardcode path to lookup for Java and will complain it can't find a functioning Java binary in the system.
to fix this, open
/opt/solr/bin/solr
at at line 217 replace:
JAVA=java
with
JAVA=/opt/jdk11/bin/java
ref https://stackoverflow.com/a/37125455 .
then you can run the
/op/solr/bin/solr
command to create / delete cores, etc.
SOLR setup
-
Apache SOLR 7.5 ( https://archive.apache.org/dist/lucene/solr/7.5.0/ )
-
Java (see installaton steps above) :
openjdk 11 2018-09-25
OpenJDK Runtime Environment 18.9 (build 11+28)
OpenJDK 64-Bit Server VM 18.9 (build 11+28, mixed mode)
using solr APIs
-
s= string -
t= text -
i= integer
some refs on building query:
https://feministsearchtool.nl/solr?q=gender OR race OR intersectionality OR transgender OR "social class"&rows=150&fl=gender_s AND a_title_statement_t AND b_title_statement_t AND title_statement_t AND imprint_b
https://feministsearchtool.nl/solr?q=gender OR race OR intersectionality OR transgender OR"social class"&rows=150