The Universe of ( ) Images Part 2
| The Universe of ( ) Images Part 2 | |
|---|---|
| Name | The Universe of ( ) Images Part 2 |
| Location | Froh! Cologne |
| Date | 2018/12/07-2018/12/09 |
| Time | 10:00-17:00 |
| PeopleOrganisations | Hackers & Designers , Froh! |
| Type | Workshop |
| Web | Yes |
| No | |

While long-held ideas of images as proof of reality are increasingly challenged, this project presents methods and processes of hands-on learning and unlearning about the production and reception of digital images.
The projects, tools and methods were developed in the context of a workshop, taking place in Amsterdam and Cologne in November and December 2018. The aim of the workshop was to collectively develop an understanding about (de)constructions, accumulation and manipulation of images and image production, – including the dominance of certain technologies relating to image making, power structures inherent in images, and omissions entailed in processes of image creation.
A temporary publication was developed for the final event. It was as a collection of tools and ideas how tool tutorial manuals, and which invites the readers to use and appropriate whatever they find useful. The binding method and standard paper sizes, allows for compiling and reshuffling the content depending on the purpose, and even allows for to add own the addition of new tools and methods of image making.







The readers were therefore addressed as users and makers at the same time and invited to join the conversation about questions such as: How can the tools we build and use shape how we publish and consume media? WhoHow can we trust our perceptions when concepts such as truthful visual representation have vanished? Can ideas of ‘subjectivity’ and ‘partial perspectives’ replace notion of objectivity and rationality? ...
During the final event all the participants exhibited their tools and projects. An additional program of online talks by Aram Bartholl, Ilan Greenberg and Adam Harvey were taking place and streamed.
- Participants:
Leith Behkhedda, Miram Chair, Roberta Esposito, Dennis Fechner, Raphaël Fischer-Dieskau, Isabel Garcia Argos, Sophie Golle, Katherina Gorodynska, Niels van Haaften, Jan Husstedt, Tiziana Krüger, Felix Rasehorn, Lisa Schirmacher, Io Alexa Sivertsen, Jurian Strik, Upendra Vaddadi, Lacey Verhalen
- Organised by:
FROH! – www.froh.ngo Hackers & Designers – www.hackersanddesigners.nl
- With the generous contributions of:
fanfare, Aram Bartholl, Ilan Greenberg, Adam Harvey, Hay Kranen, Colm O’Neill, Arthur Steiner, Leonardo Dellanoce, Coralie Vogelaar
- Thank you:
fanfare, Motoki, Atelier 4, Tara’s Keuken
Read
On The Universe of Images by Jeannette Weber
Documentation of works
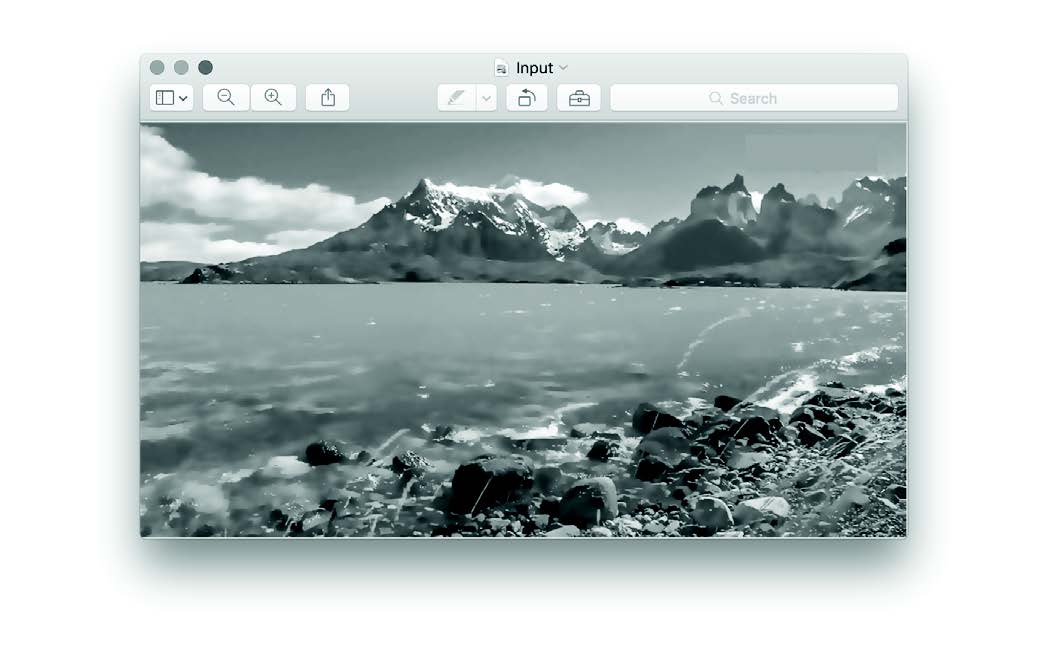
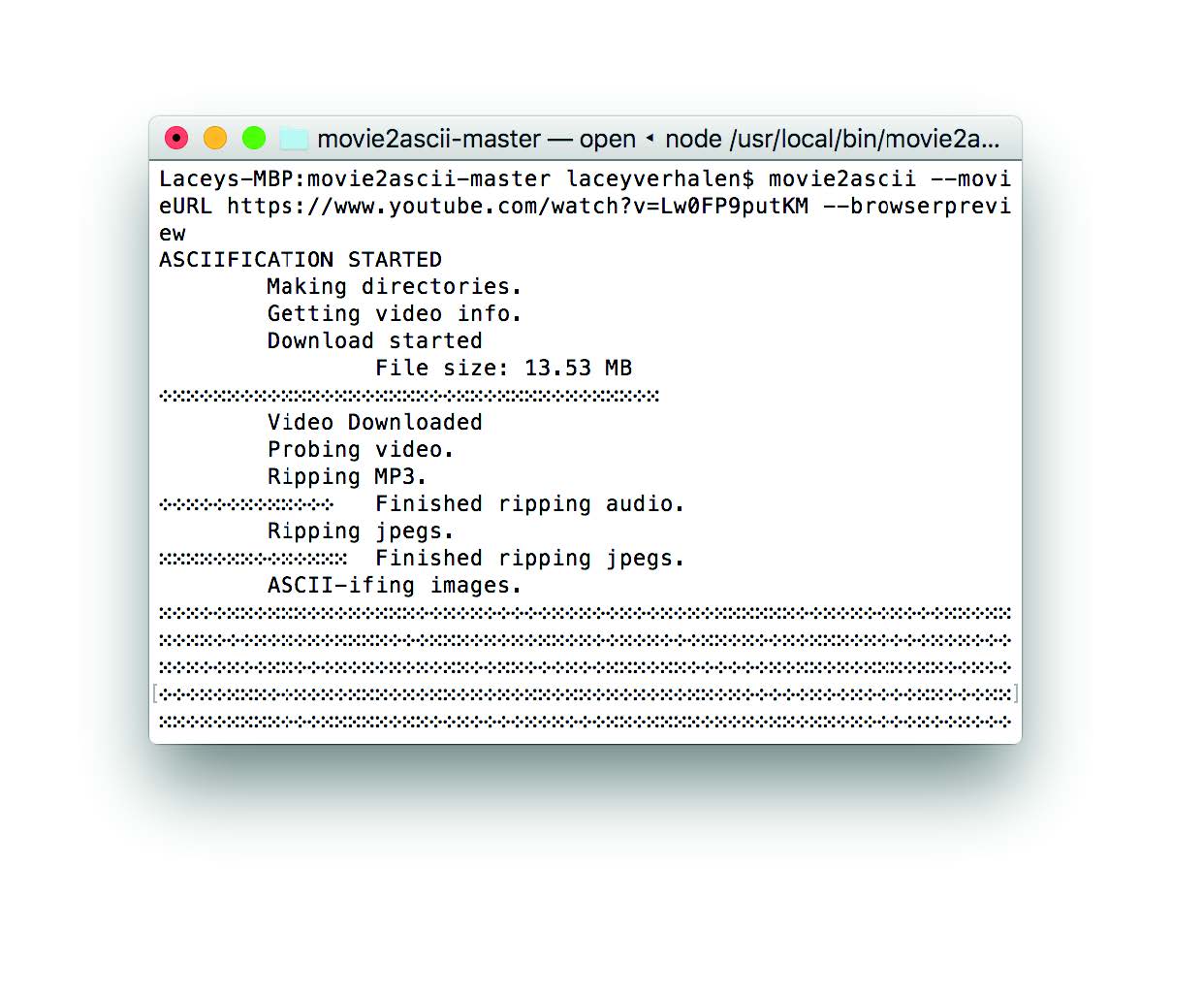
Lacey Verhalen

Process:
- Image to ASCII. Follow directions here: https://github.com/pjobson/movie2ascii Tool: Terminal
- ASCII Browser Preview to video file. Make a screenrecording. Tool: Quicktime, Kap, etc.
- Download input file. Tool: Clipgrab. https://clipgrab.org/
- Video Layering. Layer the ASCII and input video. Tool: After Effects
- Download text to embed in the image. Tool: Convert image to text. https://www.onlineocr.net/
- Complex-ify. Add text to the image manually. Tool: After Effects, Photoshop

Upendra Vaddadi
»Edible Images« is a series of zines, produced as a result of an ongoing experiment in generative publishing; and marks the starting point of such an experiment.
The idea of edible images is rooted in the critique of the aesthetic economy that food operates within today. For, our food ecologies today have come a long way from the original organic landscapes and now stand as a universe of edible images, one that is housed within the convenient space of our neighborhood supermarket. With this process, our visual grammar in relation to food has also changed drastically; from being a tactical understanding of food as it naturally grows in organic landscapes, to a comprehension of food based on the two-dimensional images that claim to represent it.
Neo-Liberalization of food, as with everything else, has led to the expropriation and subsequent extinction of many indigenous bodies of knowledge, that once stood as empirical truths. As a result, we now find ourselves not only navigating a universe of edible images, but also a maze of incoherent nutritional truths.
We are therefore, in dire need of critically filtering our notions about food and generating more public discourse than already exists. Publishing, of course, since its inception has been instrumental in making things ‘public’. But how should publications occur today in our post-truth world? Can we still depend on knowledge bodies propagated by authors and authorities? Is there a way to overcome these ego-fueled autocratic structures? Can the “binary” machine be called upon as savior? Further, can this ‘binary’ machine that is often attributed with ‘objectivity’, be employed as an effective ‘auto-critical’ mechanism; one that perpetrates ‘critical’ bodies of knowledge, thus simplifying the process of humans navigating a post-truth world?
The experiment in generative publishing thus attempts to investigate the above, by posing the machine as an ‘auto-critic’. In the spirit of agonism, the machine as an auto-critic attempts to leverage discourses on the internet to generate zines based on a certain topic. By juxtaposing data from distinctly different sources, the zine as a ‘body of knowledge’ acts more as an ironical assemblage, one that attempts to provoke.
As, the »Edible images« series acts a starting point of this experiment, the zines have not been generated automatically or seamlessly by the posited auto-critic. Instead, they have been generated through a process that is partially human, partially machine, nevertheless critical.
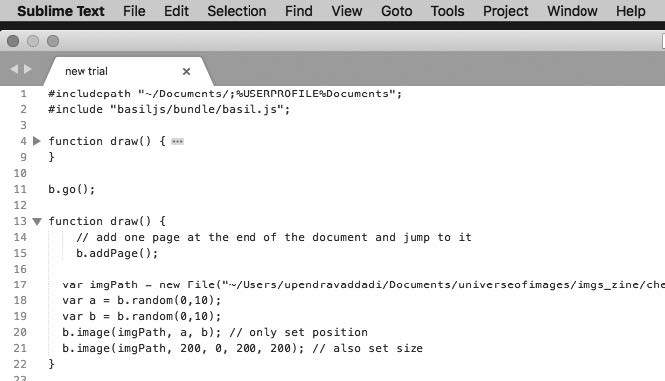
Based on a keyword, data in the form of text and image was retrieved from different corners of the internet using methods of APIs, as well as manual scraping of open databases and discursive spaces. The retrieved data was then used to create a local databank, which was used to generate the series of zines, each issue of which corresponds to the particular keyword searched for.
To know more about how the zines were made and the tools that were employed, PTO.
- RETRIEVING DATA FROM THE INTERNET.
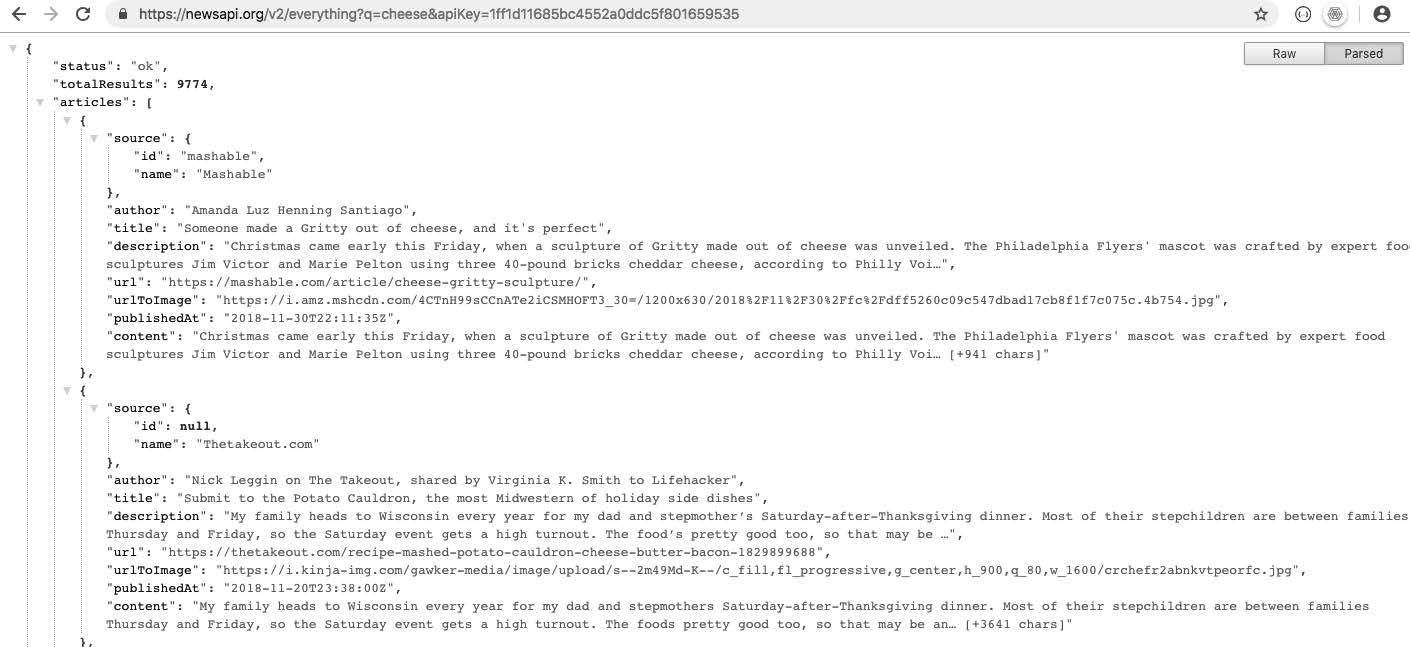
The ‘News API’ was used to get a JSON data-list of the most recent news articles published on the internet, based on a keyword search. ‘Wikimedia Commons’, ’Open-Food Facts’ and ‘Reddit’ were manually scraped for text and images using the same keyword. (In spite of the fact that each of them offers an API)
- CREATING LOCAL ‘DATABASE’.
Data retrieved from step 1 was compiled into a local folder on the computer.
- ‘GENERATING’ ZINES.
Harnessing the powers of ‘basil.js’, data was pulled from the local database to ‘design’ the zines with code, instead of the traditional InDesign GUI.
LINKS TO TOOLS & RESOURCES:
- News API - https://newsapi.org/
- Wikimedia Commons - https://commons.wikimedia.org/wiki/Main_Page
- Open Food Facts - https://world.openfoodfacts.org/data
- Reddit - https://www.reddit.com/
- Title Generator - http://www.title-generator.com/
- Basil.js - http://basiljs.ch/about/
Tiziana Krüger



Sophie Golle
What do pictures sound like?
- Convert a picture to an audio file with Photosounder, MetaSynth or Sonic Photo (for Windows only).
- Save the audio file (not possible with free demo of Photosounder and MetaSynth, but you can record the sound with Audacity and save it).
- Use the spectogramm (programme: Sonic Visualiser) to make the picture, hidden in the generated audio file, visible.
Manipulative practices of image production are not only used by the media. Celebrities and advertising industries are making use of it as well as people in power. Common practice include deleting political enemies from photos, airbrushing the face of an aged leader to revive a youthful appearance or the so-called Bedeutungs-perspektive, which is a perspective in pre-renaissance painting that sizes persons and objects according to importance. The idea of the project is three voice commands (“Delete”, “Smooth”, “King”) activating three different ways of political image processing.
Tools:
- Photosounder Demo Download: http://photosounder.com/download.php
- MetaSynth Demo Download: http://www.uisoftware.com/MetaSynth/index.php
- Sonic Photo Demo: http://www.skytopia.com/software/sonicphoto/
- Sonic Visualiser: https://sonicvisualiser.org/download.html
- Audacity: https://www.audacity.de/download-de/
Tutorials:
More Information:
- What do pictures SOUND like?: https://www.youtube.com/watch?v=YxvuDSUmuN8
- Hide Secret Messages in Audio: https://www.youtube.com/watch?v=4LP6nDRbDOA



Roberta Esposito
Travelling through the internet
Google research by images can take you very far. Starting from Cologne, I wanted to travel the internet jumping from one picture to another to see how far the research could take me. We’re used to sending postcards from our holidays to family and friends, but nowadays we are getting more used to sending selfies through messaging apps. That’s why I collected “selfie postcards” during my trip.
The steps of my research:
1st TRIAL
1. Took a selfie in Cologne
2. Uploaded it on Google research by images to see the most similar result





2nd TRIAL
3. I picked the first result and uploaded it again in the research bar and saved again the first image I got.
4. I did it several times, until I got stuck because I always got the same image as the first result.
5. This reseach is still in progress [...]
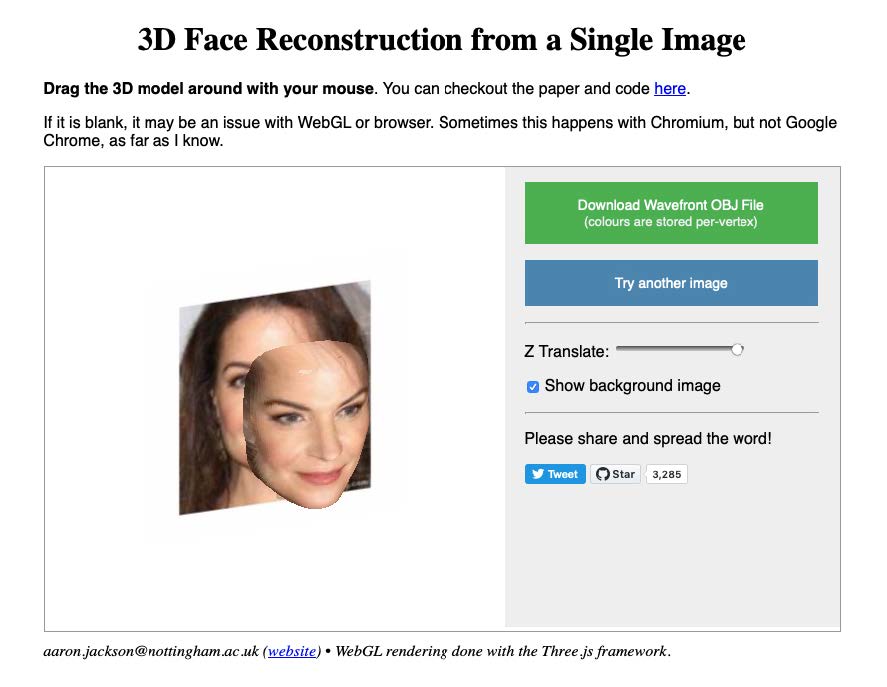
Raphaël Fischer-Dieskau
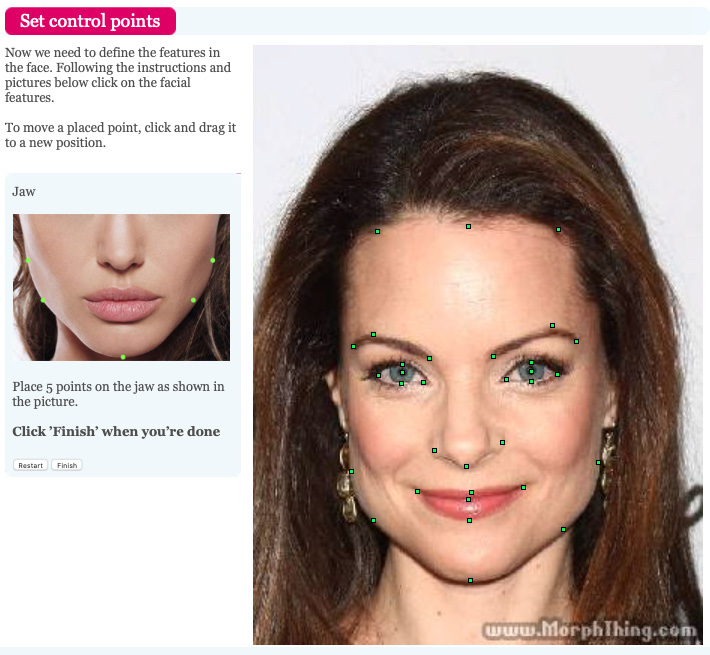
- Gathering faces from characters
- Faceswapping the two faces with free software
- Morphing the two faceswaps into one face
- Using a CNN algorithm to interpret the 2D face in a 3D mesh
- Make the 3D mesh 3D printable
- 3D print the face
- Use text to speech software for text
- Edit recordings
Lisa Schirmacher
Algorythmic Faliure
I visualize how abstract data in computers actually are and how they make up things and maybe produce faliures. Every program has its own rules of how to deal with data and therefore every digital tool influences the outcoming result and generating new data along the way. To create this experience and make it most perceptible I transferred this data in a for an human very primal space: the 3 dimensional „reality“.
In Special Case of the Portrait as a Image-Topic i think its most interesting and i am also curious about: How Identity and Personality is destroyed through reducing real images to pixels and through defining rules to read this pictures. But also in every picture: You only see what you want to see.
Step 1: Take a normal photo of a person.
Step 2: Convert in black and white with Photoshop.
Step 3: Take the highpass filter.
Step 4: Increase the contrast by using levels in Photoshop.
Step 5: Pixelate your image.
Step 6: Increase contrast by turning down brightness and increasing contrast.
Step 7: Use the website http://cvl-demos.cs.nott.ac.uk/vrn/ to convert your 2D Image into a 3D Image. Blend out the background.
Step 8: Repeat step 6 to see how the algorithm reacts.
Step 9: You can export Wavefont OBJ File to look at your Image in Cinema 4D. You have to delete the .txt at the end of the file first. Now you can make a video or something else. Have fun!










Jurian Strik
The dark side of user friendly interfaces.
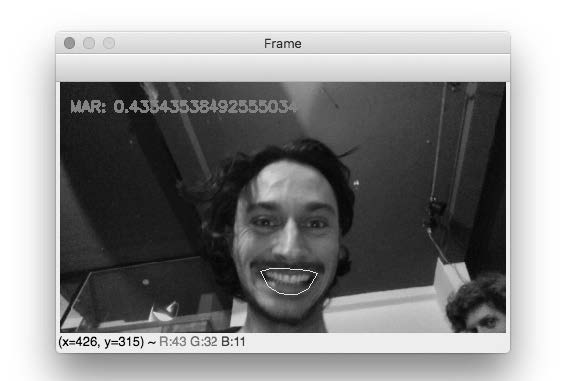

Niels van Haaften
The Viola-Jones Algorithm is the first object detection framework for object detection in real time proposed by Paul Viola and Michael Jones in 2001. The algorithm can be trained to detect a variety of objects, some of which are traffic signs, cars and most famously faces. By detecting various objects and people within a space and the ability to track their movement the Viola-Jones algorithm and all of its offspring have become a player within our 3D world.
Step 1 From an array to a 2D image
A picture is basically one big array (a kind of list) filled with all the RGB values of the picture. So every three pixels represent the color of one pixel. In order for the algorithm to be able to read it as a 2D image, it first has to be rebuild as an 2d image. There is a specific section of looped code in order to do that. Within the loop the object detection takes place.

With loc being the location of the pixel in the array of the video file. And x and y being it’s location within the 2d image*
Step 2 Looking at contrast within the image
The algorithm detects objects by looking at the Haar features of an object. Haar features are specific strongly contrasting areas within the image of an object. So with the front of a car for example, the bottom area is always a lot darker than the hood of the car.

Because Haar features are only a weak learner or classifier (its detection quality is slightly better than random guessing) a large number of Haar-like features are necessary to describe an object with sufficient accuracy. And in the case of a car for example you will need differents sets of Haar features for the font, the sides and the back of the car.
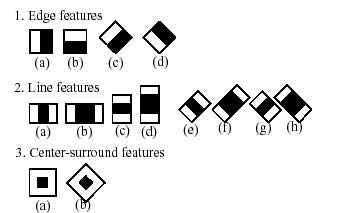
Because of the large number of Haar-like features that are necessary to detect an object the detection proces is split up in different cascades. A cascade is a smaller set of Haar-like features of which the first is used to quickly detect if there is a chance of a car being in that part of the picture. The second is to detect it with even more certainty and so on....
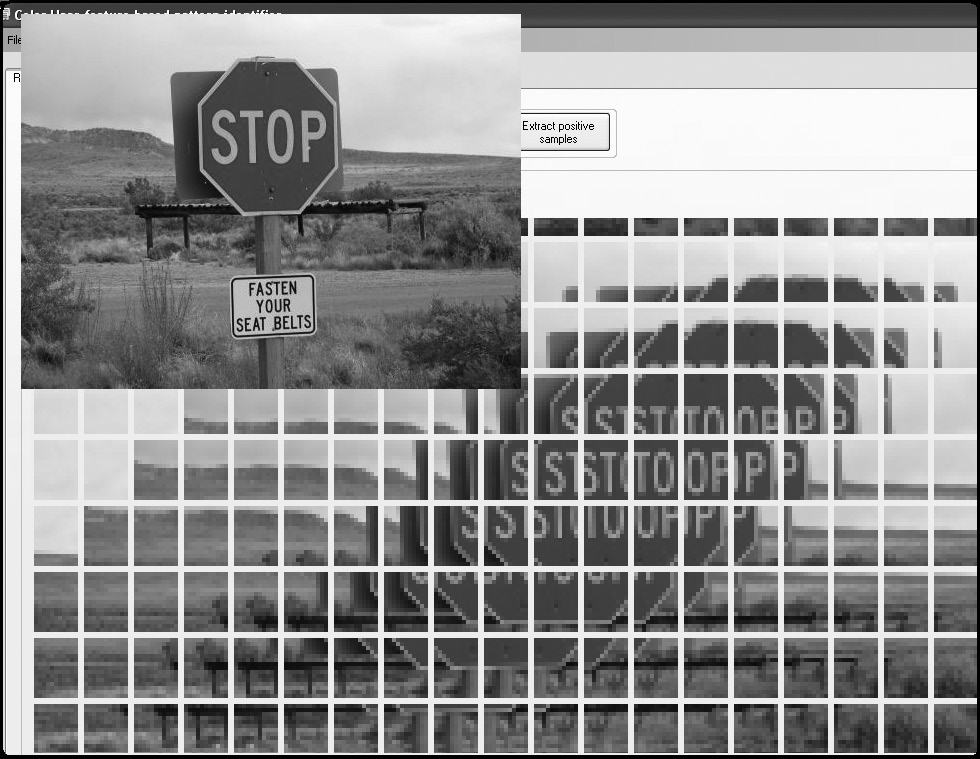
Step 3 Training the algorithm
In order for the viola jones algorithm to be able to know what an object looks like the algorithm first needs to learn what it looks like. This proces takes place by feeding it a lot of positive images (images of faces) and negative images (images without faces) to train the classifier by extracting the haar-like features from those images.
Based on coding within the Java framework Processing
Miriam Chair
Are you able to recognize faces?
I was fascinated by humans that are (still) able to process faces better then computer softwares. In 2009 it was discovered that there a people that can remember faces and recognize them after years and with changes of their appearance, even if they only saw them a few times. They are called ‘Super Recognizers.’ These people are not only interesting for scientist but also used in criminal cases. Different to most softwares that need a lot of input photos to recognize someone and are unable to look over changes of hair/beard/hat etc. Super Recognizers can identify persons on surveillance cameras and in real life just after seeing them on a photo. With a photobooth application I wanted to engage visitors to make a photo of themself or someone else and in a second step gave them a minute to look at it and draw from their memory.
Photobooth in Processing
- Install Processing and Import the Video Library
- Activate the webcam of your computer with the processing application https://processing.org/reference/libraries/video/Capture.html https://www.youtube.com/watch?v=WH31daSj4nc (video tutorial)
- To make a snapshot by clicking the mouse ad this to void setup(): if mousePressed(); { video.read(); //to save the image add: saveFrame(“Folder/####.jpg”) }
- There are different filters to stylize the image under the line void draw(); https://processing.org/reference/filter_.html
Katherina Gorodynska
Eliza is a mock Rogerian psychotherapist. The original program was described by Joseph Weizenbaum in 1966. Mitsuku is an artificial intelligence that you can talk to like a real person at www.mitsuku.com. Hi, I am the worlds most humanlike conversational AI REPLICA. Whether you are feeling overwhelmed, alone, or just need to chat, Replica is here for you. Zo Your AI friend, here to talk whenever you need it. Discover new things about yourself with every conversation. Rose is a yuppie who has an unorthodox family and quirky attitudes to life. You will find her secretive on some subjects as her work has made her aware how under surveillance we all are. Alexa calls itself female in character. Would you rather your virtual assistent be male, female, or gender neutral? Male 9 % Gender neutral 7 % I do not have a preference 24 % Other 1 % Female 58 % https://www.androidauthority.com/virtual-assistant-voice-poll-886294/
Analyzing Image.... What image do you have of me while we are chatting? Why do you need an image? Can you draw me? How do I look like? How does my interface look like? If swimming is such a good exercise, why are whales fat?
Dennis Fechner

First part of the workshop: 23–25 November in Amsterdam!
The project The Universe of [ ] Images is funded by
Fonds Soziokultur
and
Fonds voor Cultuurparticipatie

{kind=link}
{kind=link}